

von
Matthieu Lienart
Cloud Engineer, aus Ostermundigen
Cloud Engineer, aus Ostermundigen
LangChain bei AWS CloudWatch protokollieren
LangChain ist ein beliebtes Framework für die Entwicklung von Anwendungen, die auf grossen Sprachmodellen basieren. Es bietet Komponenten für die Arbeit mit LLMs über zusammensetzbare Ketten und Agenten. Bei der Entwicklung von Produktionsanwendungen mit LangChain wird eine korrekte Protokollierung für die Überwachung, das Debuggen und die Prüfung deiner KI-Systeme unerlässlich. AWS CloudWatch ist die natürliche Wahl für die Protokollierung in meinem serverlosen Kontext und bietet zentralen Protokollspeicher, Metriken und leistungsstarke Analysefunktionen.
Wo liegt das Problem?
In meinem vorherigen Artikel «Ein serverloser Chatbot mit LangChain & AWS Bedrock» habe ich eine Lösung für einen serverlosen Chatbot mit LangChain und AWS Bedrock vorgestellt, mit allen Funktionen von:
- Verlauf der Konversationen
- In der Benutzersprache antworten
- Benutzerdefinierter Kontext mit RAG
- Leitplanken modellieren
- Strukturierte Ausgabe
Da die beschriebene Lösung darauf abzielt, auf AWS Lambda zu laufen, möchte ich natürlich all diese Logs nach AWS CloudWatch exportieren.
Das Problem ist, dass allein die Verwendung der Funktion langchain.globals.set_debug ausführliche, unstrukturierte Logs erzeugt, die in CloudWatch praktisch unbrauchbar werden. Diese Logs sind schwer zu lesen, mit CloudWatch Insights nicht effektiv abzufragen und es fehlt ihnen der Kontext, der für ein richtiges Debugging erforderlich ist. Damit CloudWatch seinen vollen Nutzen entfalten kann, müssen Logs in einem strukturierten JSON-Format mit konsistenten Feldern und aussagekräftigen Metadaten gespeichert werden, die programmatisch gefiltert und analysiert werden können.
Das Problem ist, dass allein die Verwendung der Funktion langchain.globals.set_debug ausführliche, unstrukturierte Logs erzeugt, die in CloudWatch praktisch unbrauchbar werden. Diese Logs sind schwer zu lesen, mit CloudWatch Insights nicht effektiv abzufragen und es fehlt ihnen der Kontext, der für ein richtiges Debugging erforderlich ist. Damit CloudWatch seinen vollen Nutzen entfalten kann, müssen Logs in einem strukturierten JSON-Format mit konsistenten Feldern und aussagekräftigen Metadaten gespeichert werden, die programmatisch gefiltert und analysiert werden können.
Die Lösung
Im Wesentlichen habe ich ein strukturiertes Protokollierungssystem erstellt, das die ausführliche Textausgabe von LangChain in ein CloudWatch-freundliches strukturiertes JSON-Format umwandelt. Diese Lösung ermöglicht eine effektive Überwachung, Fehlerbehebung und Analyse der LangChain-Anwendungen in einer AWS-Umgebung.
Ich verwende einen LangChain-Callback, um LangChain-Aktionen zu erfassen, die Protokolle zu formatieren und sie mit dem AWS Lambda PowerTools Logger an CloudWatch zu senden. Ein Vorteil dieses benutzerdefinierten Ansatzes ist, dass Logs mit benutzerdefinierten Metadaten, wie einer Sitzungs- oder Benutzer-ID, angereichert werden können.
Ich verwende einen LangChain-Callback, um LangChain-Aktionen zu erfassen, die Protokolle zu formatieren und sie mit dem AWS Lambda PowerTools Logger an CloudWatch zu senden. Ein Vorteil dieses benutzerdefinierten Ansatzes ist, dass Logs mit benutzerdefinierten Metadaten, wie einer Sitzungs- oder Benutzer-ID, angereichert werden können.
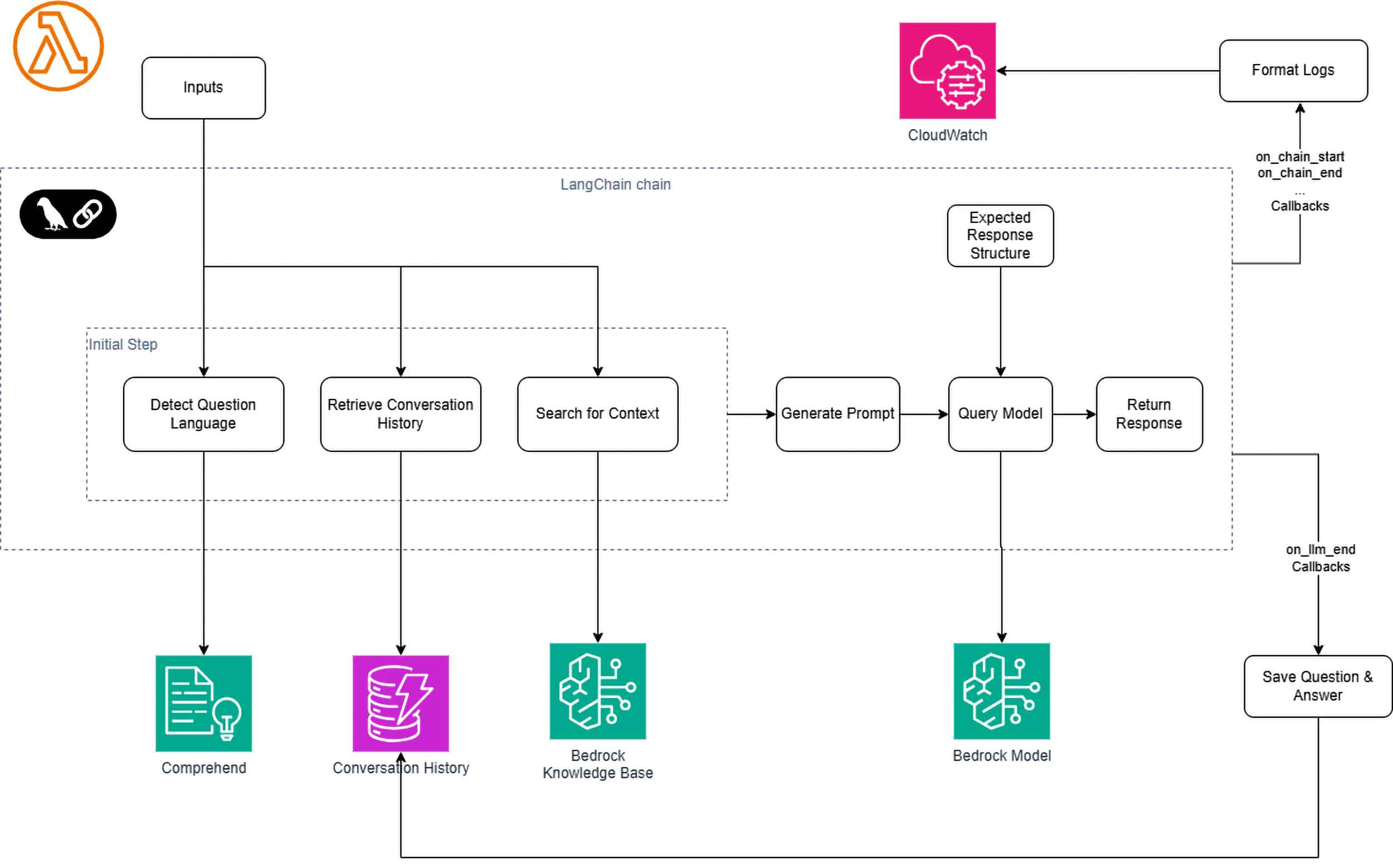
Abbildung 1: High-Level-Architektur des serverlosen Chatbots
Den vollständigen Code findest du im Jupyter-Notebook in diesem GitHub-Repository. Während das Notebook die Komponenten lokal demonstriert, gelten die Prinzipien direkt für die Bereitstellung einer Lambda-Funktion.
Einen Callback für die Protokollierung verwenden
Der Ansatz, den ich hier verwende, besteht darin, LangChain-Callbacks für Aktionen wie on_chain_start, on_chain_end, on_chain_error, usw. zu verwenden, um die Aktionen in der Kette zu erfassen und zu protokollieren.
Da die Nachrichten von Kettenaktionen oder LLM-Aufforderungen und Antworten lang sein können und vertrauliche Informationen enthalten, stelle ich Parameter wie exclude_inputs, exclude_outputs für den Callback zur Verfügung, um solche Inhalte redigieren zu können.
Die vollständige Liste der LangChain-Rückrufe ist hier verfügbar.
Der Logging-Rückruf ist wie folgt strukturiert:
Die vollständige Liste der LangChain-Rückrufe ist hier verfügbar.
Der Logging-Rückruf ist wie folgt strukturiert:
class LoggingHandler(BaseCallbackHandler):
def __init__(
self,
session_id: str,
exclude_inputs: bool = False,
exclude_outputs: bool = False,
):
self.session_id = session_id
self.exclude_inputs = exclude_inputs
self.exclude_outputs = exclude_outputs
def _parse_dict_values(…):
…
def on_chain_start(…):
…
def on_chain_end(…):
…
def on_llm_start(…):
…
def on_llm_end(…):
…
def on_chain_error(…):
…
def on_llm_error(…):
…
Analysieren der Logs
Eingaben, Ausgaben, Eingabeaufforderungen, Modellantworten usw., die den Inhalt der Rückrufe ausmachen, sind Wörterbücher, die serialisierbare LangChain-Objekte enthalten. Um diese Daten vorzubereiten und sicherzustellen, dass alle verschachtelten Objekte in Standard-Python-Typen konvertiert werden, die von CloudWatch Logs problemlos verarbeitet werden können, muss es das Wörterbuch rekursiv durchgehen und die LangChain-Objekte serialisieren. Das wird durch die Hilfsfunktion _parse_dict_values () erledigt.
def _parse_dict_values(self, obj: Any) -> Any:
if isinstance(obj, Serializable):
return obj.model_dump()
if isinstance(obj, dict):
return {k: self._parse_dict_values(v) for k, v in obj.items()}
if isinstance(obj, list):
return [self._parse_dict_values(item) for item in obj]
return obj
LangChain-Schritte protokollieren
LangChain-Schritte wie on_chain_start, on_chain_end, zu protokollieren, beinhaltet dann
- Den Inhalt redigieren, wenn du dazu aufgefordert wirst
- Sonst serialisiere den Inhalt.
- Dann logge dich bei CloudWatch ein.
def on_chain_start(
self,
serialized: dict,
inputs: dict,
run_id: UUID,
parent_run_id: UUID | None = None,
tags: list[str] | None = None,
metadata: dict | None = None,
**kwargs,
) -> Any:
if self.exclude_inputs:
sanitized_inputs = ""
else:
sanitized_inputs = self._parse_dict_values(inputs)
logger.info(
{
"callback": "chain/start",
"action_name": self._get_name_from_callback(serialized, **kwargs),
"session_id": self.session_id,
"run_id": str(run_id),
"parent_run_id": str(parent_run_id),
"inputs": sanitized_inputs,
"tags": tags,
"metadata": metadata,
}
)
def on_chain_end(
self, outputs: dict, run_id: UUID, parent_run_id: UUID | None = None, **kwargs
) -> Any:
if self.exclude_outputs:
sanitized_outputs = ""
else:
sanitized_outputs = self._parse_dict_values(outputs)
logger.info(
{
"callback": "chain/end",
"action_name": self._get_name_from_callback(serialized, **kwargs),
"session_id": self.session_id,
"run_id": str(run_id),
"parent_run_id": str(parent_run_id),
"outputs": sanitized_outputs,
"tags": kwargs.get("tags", []),
}
)
Die Funktion _get_name_from_callback() ist eine weitere Hilfsfunktion, die versucht, den Aktionsnamen je nach Dateninhalt auf unterschiedliche Weise zu extrahieren. Den vollständigen LoggingHandler-Code mit allen Callbacks und Hilfsfunktionen finden Sie im Jupyter-Notebook.
Die Ergebnisse
Die Protokolle sind wie gewünscht formatiert, bereit für den AWS Lambda Power Tools-Logger und AWS CloudWatch, wie in einem Beispiel unten gezeigt.
{
"level": "INFO",
"location": "on_chain_start:122",
"message": {
"callback": "chain/start",
"action_name": "RunnableSequence",
"session_id": "cda54b41-8c10-47f9-87f8-f0c04a96731a",
"run_id": "0174cf48-b8f3-4418-8d7c-13b9b0881938",
"parent_run_id": "None",
"inputs": {
"question": "Wie stimmen Sie die Entwicklung eng mit den Unternehmenszielen ab?"
},
"tags": [],
"metadata": {}
},
"timestamp": "2025-06-05 13:26:14,029+0000",
"service": "service_undefined",
"cold_start": false,
"function_name": "my-function",
"function_memory_size": "128",
"function_arn": "arn:aws:lambda:us-east-1:************:function: my-function ",
"function_request_id": "1ef2901b-a061-40a5-9a4e-eb20ea80fc1b",
"xray_trace_id": "1-68419af5-730d439a2c0074857ace2227"
}
Beachte, dass der Logeintrag Folgendes enthält:
- Standardmässige CloudWatch-Felder wie Level, Zeitstempel und Lambda-Ausführungskontext
- Unser benutzerdefiniertes Nachrichtenobjekt mit LangChain-spezifischen Informationen
- Benutzerdefinierte Metadaten wie die session_id, die es ermöglichen, die Protokolle der gesamten Konversation eines Benutzers zu verfolgen
- Der tatsächliche Inhalt der Eingaben (die redigiert werden könnten, wenn sie sensibel sind)
Mit diesem strukturierten Format kannst du CloudWatch Insights verwenden, um leistungsstarke Abfragen auszuführen wie:
fields @timestamp, @message | filter message.session_id = "cda54b41-8c10-47f9-87f8-f0c04a96731a" | sort @timestamp asc
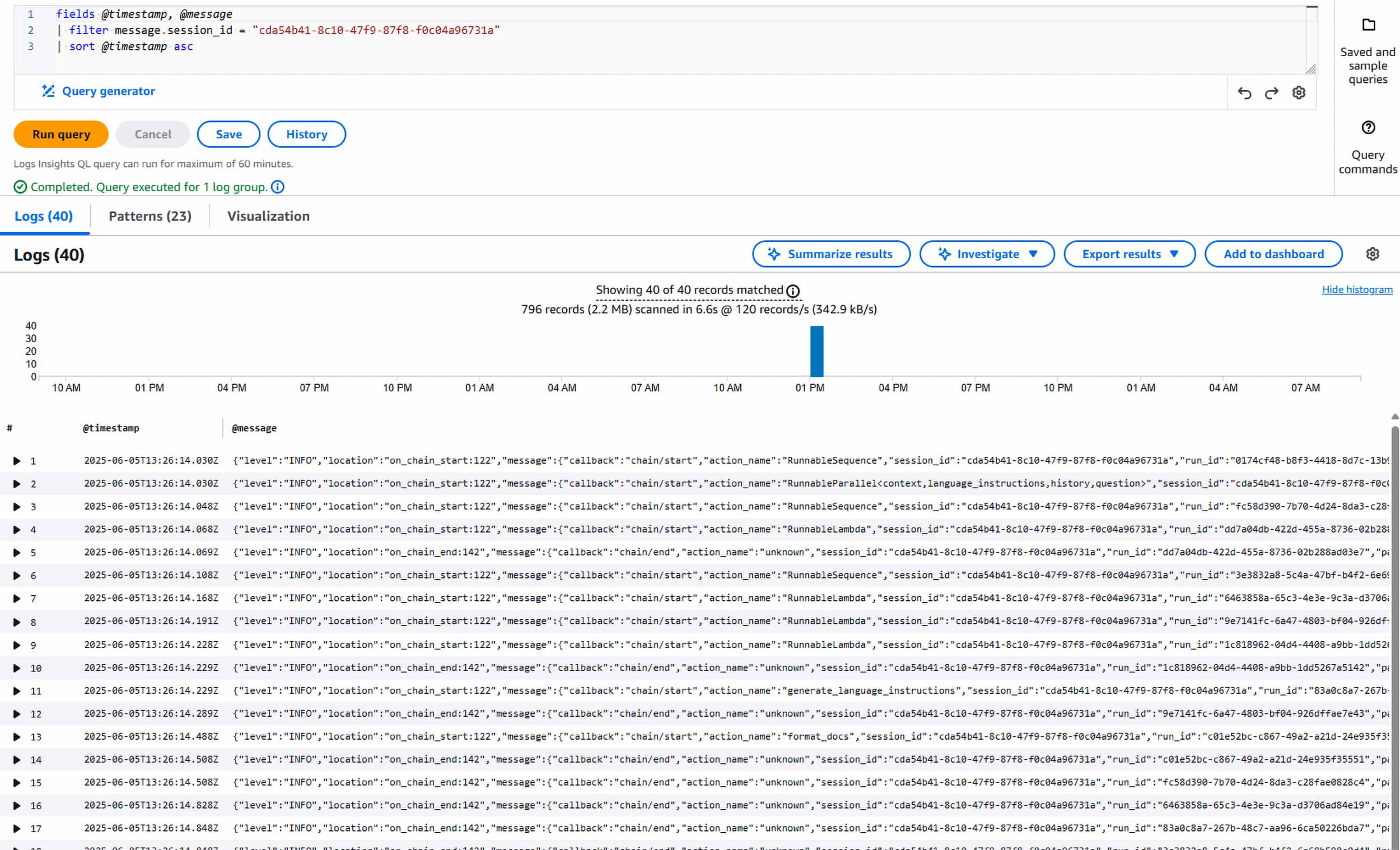
Bild 1: Alle LangChain-Logs für eine bestimmte Benutzersitzung abrufen
Wichtige Erkenntnisse
Aufbauend auf meinem vorherigen Artikel über serverlose LangChain-Anwendungen hat diese Protokollierungsimplementierung zusätzliche Erkenntnisse ergeben, die es wert sind, geteilt zu werden:
- CloudWatch-freundliche Protokollierung ist wichtig: Einfach die nativen Logs von LangChain auf CloudWatch zu übertragen, schafft mehr Probleme als es löst. Das Entwerfen von Protokollen speziell für die Abfragefunktionen von CloudWatch ermöglicht eine effektive Überwachung und Analyse.
- Ausgewogenheit zwischen Details und Datenschutz: Wenn du LLM-Interaktionen protokollierst, musst du sorgfältig abwägen, genügend Details für das Debugging zu erfassen und sensible Informationen zu schützen, die in Eingabeaufforderungen und Antworten enthalten sein könnten. Der hier vorgestellte parametrisierte Redaktionsansatz bietet eine flexible Lösung.
- Benutzerdefinierte Rückrufe bieten Kontrolle: LangChain bietet zwar integrierte Logging-Funktionen, aber benutzerdefinierte Callbacks geben dir präzise Kontrolle darüber, was protokolliert und wie es formatiert wird, was für Produktionsumgebungen unerlässlich ist.


