

Cloud Engineer, aus Ostermundigen
Ein Serverless Chatbot mit LangChain & AWS Bedrock
LangChain ist ein Open-Source-Framework für die Entwicklung von Anwendungen, die auf grossen Sprachmodellen (LLMs) basieren, während AWS Bedrock ein vollständig verwalteter Service ist, der Zugriff auf Basismodelle von führenden KI-Unternehmen bietet. Ich weiss, heutzutage dreht sich alles um agentische KI, aber selbst wenn du versuchst, mit LangChain und AWS Bedrock einen einfachen serverlosen, nicht agentischen Chatbot zu entwickeln, musst du trotzdem viele erweiterte Funktionen kombinieren.
Dieser Artikel führt dich durch die Herausforderungen bei der Integration dieser leistungsstarken Tools, um einen ausgeklügelten Chatbot mit Funktionen wie Verwaltung des Konversationsverlaufs, Retrieval-Augmented Generation (RAG), mehrsprachigem Support und mehr zu erstellen.
Wo liegt das Problem?
- Die Fähigkeit, die aktuelle Konversation aufrechtzuerhalten (hier beschränke ich den Umfang auf die aktuelle Konversation, nicht das Speichern vergangener Interaktionen).
- Stelle dem Modell mithilfe deiner Wissensdatenbank deinen eigenen spezifischen Kontext zur Verfügung und verwende Retrieval-Augmented Generation (RAG), um Antworten zu generieren, die sich auf deinen Kontext beziehen (hier beschränke ich mich auf gecrawlte Webseiten).
- Die Fähigkeit, in der Sprache des Benutzers zu antworten.
- Leitplanken, um sicherzustellen, dass die Antworten deinen Chatbot-Zielen entsprechen, um schnelle Angriffe zu verhindern usw.
- Die Fähigkeit, Ausgaben direkt in einem strukturierten JSON-Format für das Frontend zu generieren.
Zumindest wollte ich all diese Dinge.
Es gibt zwar zahlreiche Codebeispiele und Tutorials, die eine oder zwei dieser Funktionen demonstrieren, aber ich habe keines gefunden, das alle fünf umfassend abdeckt. Darüber hinaus basieren viele der vollständigeren Beispiele auf veralteten Versionen von LangChain mit veralteten APIs.
Dieser Artikel zielt darauf ab, die Lücke zu schliessen, obwohl er angesichts des Innovationstempos in diesem Bereich schnell veraltet sein könnte.
Die Lösung
- Für die Verwaltung des Konversationsverlaufs verwende ich DynamoDB und LangChain, um den Konversationsverlauf zu speichern, aber ich implementiere eine benutzerdefinierte Lösung, anstatt das gemeinsame RunnableWithMessageHistory zu verwenden.
- Für mehrsprachigen Support verwende ich AWS Comprehend, um die Sprache der Frage zu erkennen und entsprechende Sprachanweisungen für die Antwort des Modells zu generieren. Die Spracherkennung könnte auch mit einem LLM durchgeführt werden, aber ich vermute (obwohl ich es nicht getestet habe), dass die Reaktionszeit und die Kosten höher wären.
- Ich verwende die integrierten Funktionen von Bedrock für die RAG-Wissensdatenbank (mit dem integrierten Webcrawler zur Indexierung der Inhalte, die hier nicht gezeigt werden), für Leitplanken und für die Generierung strukturierter JSON-Ausgaben.
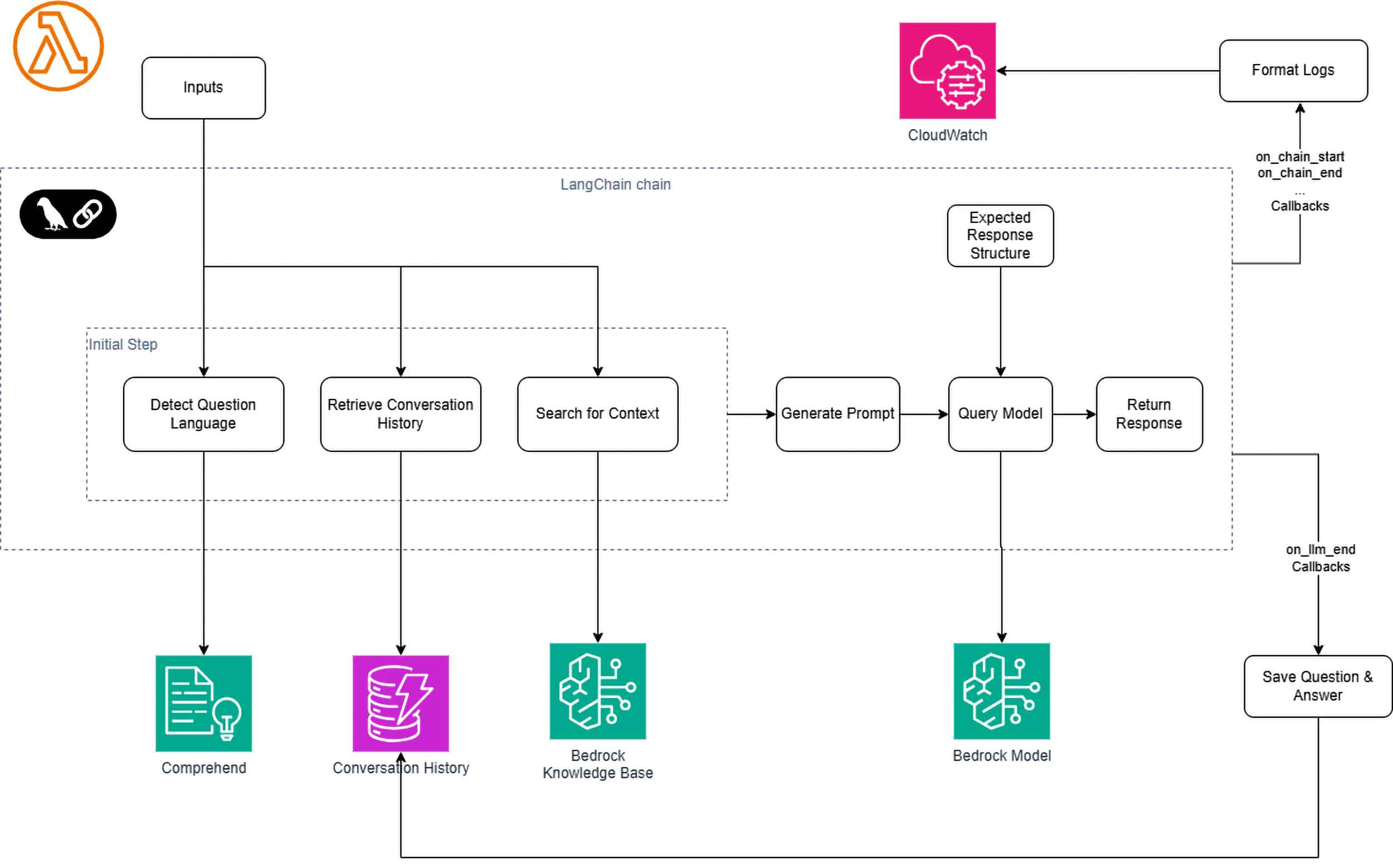
Abbildung 1: High-Level-Architektur des serverlosen Chatbots
Den vollständigen Code findest du im Jupyter-Notebook in diesem GitHub-Repository. Während das Notebook die Komponenten lokal demonstriert, gelten die Prinzipien direkt für die Bereitstellung einer Lambda-Funktion.
Einzelheiten
1 | Verwalte den Konversationsverlauf
Warum nicht den Konversationsverlauf mit RunnableWithMessageHistory verwalten?
- Leistungseinschränkungen: RunnableWithMessageHistory-Klasse ruft den Konversationsverlauf ab, bevor die Kette ausgeführt wird. Aber in meiner Implementierung muss ich drei unabhängige Aufgaben ausführen: a) Abrufen des RAG-Kontextes, b) Spracherkennung und Befehlsgenerierung, c) Abrufen des Konversationsverlaufs. Durch die Parallelisierung dieser Aufgaben kann ich die Latenz der ursprünglichen LangChain reduzieren.
- Inkompatibilität mit strukturierter Ausgabe: Die Standardimplementierung funktioniert nicht gut mit strukturierter Ausgabe. Das kann zwar umgangen werden, indem die Rohausgabe immer zusammen mit der strukturierten Ausgabe zurückgegeben und die Rohausgabe im Nachrichtenverlauf gespeichert wird, aber es führt zu einem neuen Problem. Es würde unnötige Informationen wie RAG-Verweise in den Konversationsverlauf aufnehmen, die LLM-Eingabeaufforderungstoken verbrauchen würden, wenn diese Historie in späteren Eingabeaufforderungen verwendet würde. Also, ich muss anpassen, was in der Datenbank gespeichert ist.
Parallelisierung des Abrufs des Konversationsverlaufs
history = DynamoDBChatMessageHistory( table_name=CONVERSATION_HISTORY_TABLE_NAME, session_id=session_id, key=this_session_key, )
RunnableParallel({
"references": …,
"language_instructions": …,
"history": RunnableLambda(lambda x: history.messages),
"question": …
})
})


Der erste Trace zeigt den sequentiellen Charakter von RunnableWithMessageHistory, bei dem der Konversationsverlauf vor anderen Aufgaben abgerufen wird. Im Gegensatz dazu zeigt der zweite Trace, wie meine benutzerdefinierte Implementierung die gleichzeitige Ausführung des RAG-Abrufs, der Spracherkennung und des Abrufs des Konversationsverlaufs ermöglicht, was zu einer verbesserten Gesamtleistung führt. Die Latenz der ersten Schritte vor dem Aufruf des LLM-Modells wurde von 1,2 Sekunden auf 1,0 Sekunden verbessert, indem der Abruf des Konversationsverlaufs von DynamoDB parallelisiert wird.
Einen Callback-Handler zum Speichern von Nachrichten verwenden
- Extrahiere nur die relevanten Teile der Antwort des Modells für die Lagerung
- Trenne die Antwort von den Referenzen
- Minimiere die Token-Nutzung in zukünftigen Eingabeaufforderungen
class StoreMessagesCallbackHandler(BaseCallbackHandler):
def __init__(self, history: BaseChatMessageHistory, session_id: str, question: str):
self.history = history
self.session_id = session_id
self.question = question
def on_llm_end(self, response: LLMResult, **kwargs) -> Any
:
logger.info("Storing question and LLM answer back into DynamoDB")
generations = response.generations
if generations and len(generations) > 0 and generations[0] and len(generations[0]) > 0:
response_message = generations[0][0].message
ai_message_kwargs = response_message.model_dump()
if isinstance(response_message.content, list) and response_message.content:
input = response_message.content[0].get("input")
ai_message_kwargs["content"] = input.get("answer")
ai_message_kwargs["references"] = input.get("references")
self.history.add_messages([
HumanMessage(content=self.question),
AIMessage(**ai_message_kwargs)
])
else:
logger.warning("No generations returned by LLM; no AI message to store.")
self.history.add_message(HumanMessage(content=self.question))
Es ist aus zwei Gründen wichtig, die Anzahl der Tokens so gering wie möglich zu halten:
- Model-Eingabeaufforderungen haben eine Beschränkung in der Anzahl der Eingabe-Token,
- Wir zahlen pro verwendetem Token.
In meinem Anwendungsfall besteht die Musterantwort aus zwei Teilen: der Antwort und einer Referenzliste (einschliesslich URLs und Auszügen). Für zukünftige Interaktionen ist nur die Textantwort wirklich notwendig, damit das Model der Konversation folgen kann. Indem ich nur die Antwort und nicht die Referenzen speichere, kann ich die Token-Nutzung bei nachfolgenden Eingabeaufforderungen deutlich reduzieren.
2 | RAG-Abruf
kb_retriever = AmazonKnowledgeBasesRetriever(
client=bedrock_agent_client,
knowledge_base_id=BEDROCK_KNOWLEDGE_BASE_ID,
retrieval_config={"vectorSearchConfiguration": {"numberOfResults": 4}},
)
itemgetter("question") | kb_retriever | format_references
3 | Sprachanweisungen generieren
def generate_language_instructions(question: str) -> str:
try:
response = comprehend_client.detect_dominant_language(Text=question)
logger.info(f"Comprehend language detection response: {response}")
if languages := response.get("Languages"):
# Sort languages by score and return the one with the highest score
languages.sort(key=lambda x: x["Score"], reverse=True)
dominant_language = languages[0]["LanguageCode"]
logger.info(f"Detected language: {dominant_language}")
return f"Answer the question in the provided RFC 5646 language code: '{dominant_language}'."
logger.warning("No language detected, defaulting to basic instructions.")
return "Answer in the same language as the question."
except Exception as e:
logger.error(f"Error detecting language: {e}")
logger.warning("Defaulting to basic language instructions.")
return "Answer in the same language as the question."
itemgetter("question") | RunnableLambda(generate_language_instructions)
4 | Leitplanken benutzen
llm = ChatBedrockConverse(
client=bedrock_client,
model=BEDROCK_MODEL,
verbose=True,
max_tokens=2048,
temperature=0.0,
top_p=1,
stop_sequences=["\n\nHuman"],
guardrail_config={
"guardrailIdentifier": BEDROCK_GUARDRAIL_ID,
"guardrailVersion": BEDROCK_GUARDRAIL_VERSION
}
)
5 | Strukturierte Ausgabe
class ChatBotResponseReference(BaseModel):
"""A web reference used to answer the question"""
url: str = Field(description="The URL of the reference")
excerpt: str = Field(description="The extract from the reference")
class ChatBotResponse(BaseModel):
"""The response from the chatbot."""
answer: str = Field(description="The answer to the question")
references: list[ChatBotResponseReference] = Field(description="A list of references relating to the question")
structured_llm = llm.with_structured_output(
ChatBotResponse,
include_raw=True,
)
Bei diesem Ansatz besteht immer noch das Risiko, dass das Modell halluziniert und, anstatt die Referenzen, die du ihm gibst, wiederzuverwenden, in der Antwort nicht existierende Referenzen generiert. Wenn du mit einem solchen Problem konfrontiert bist und dem Benutzer die genauen Ergebnisse aus dem Schritt zum Abrufen der RAG-Knowledge-Base geben musst, besteht die Lösung darin, das Modell nicht zu bitten, eine strukturierte Ausgabe mit Referenzen zu generieren. Stattdessen erstellst du einen ersten LangChain initial_step wie unten, aber du rufst ihn zuerst auf, um die Eingabeaufforderung zu generieren. Dann übergibst du das als Eingaben, wenn du die prompt|llm Kette aufrufst. Du kombinierst dann den Inhalt der LLM-Antwort mit den Referenzen, die du im ersten Schritt gesammelt hast.
Die LangChain-Kette
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an assistant for question-answering tasks. Use the following pieces of retrieved references to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Here is a list of web pages references to be used as context to answer the question.
Copy-paste them together with your answer in the output:
{references}
{language_instructions}\n """
),
MessagesPlaceholder(variable_name="history"),
("human", "{question}"),
]
)
initial_step = RunnableParallel({
" references ": itemgetter("question") | kb_retriever | format_references,
"language_instructions": itemgetter("question") | RunnableLambda(generate_language_instructions),
"history": RunnableLambda(lambda x: history.messages),
"question": itemgetter("question"),
})
full_chain = (
initial_step
| prompt
| structured_llm
)
question = "C'est quoi LangChain?"
chain_callbacks = [
StoreMessagesCallbackHandler(history, session_id, question),
CloudWatchLoggingHandler(session_id)
]
response = full_chain.invoke({"question":question }, {"callbacks": chain_callbacks})
Die Ergebnisse
- Die mehrsprachige Konversation: Wir werden sehen, wie der Chatbot eine mehrstufige Konversation auf Französisch handhabt und seine Spracherkennungs- und Antwortfähigkeiten demonstriert
- Die generierten Eingabeaufforderungen: Wir werden die durch mein LangChain-Setup erstellten Eingabeaufforderungen untersuchen und zeigen, wie der Konversationsverlauf und der Kontext integriert sind.
- Die DynamoDB-Tabelle für den Nachrichtenverlauf: Wir überprüfen, wie die Konversation in der DynamoDB-Tabelle gespeichert wird, um die Persistenz über Interaktionen hinweg sicherzustellen.
Die Konversation
System: You are an assistant for question-answering tasks. Use the following pieces of retrieved context references to answer the question. Use three sentences maximum and keep the answer concise.
Here is a list of web pages references to be used as context to answer the question. Copy-paste them together with your answer in the output:
[
{
"url": "https://python.langchain.com/docs/introduction/",
"excerpt": "LangChain is a framework for developing applications powered by large language models (LLMs)."
}
]
Answer the question in the provided RFC 5646 language code: 'fr'.
Human: C'est quoi LangChain?
{
"answer": "LangChain est un framework open-source pour développer des applications basées sur des modèles de langage.",
"references": [
{
"url": "https://python.langchain.com/docs/introduction/",
"excerpt": "LangChain is a framework for developing applications powered by large language models (LLMs)."
}
]
}
{
"answer": "LangChain est compatible avec AWS Bedrock, permettant l’intégration et l’utilisation des modèles de langage fournis par AWS.",
"references": [
{
"url": " https://python.langchain.com/docs/integrations/chat/bedrock/",
"excerpt": " Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs)"
}
]
}
System: You are an assistant for question-answering tasks. Use the following pieces of retrieved references to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Here is a list of web pages references to be used as context to answer the question. Copy/paste them together with your answer in the output:
[…]
Answer the question in the provided RFC 5646 language code: 'fr'.
Human: C'est quoi LangChain?
AI: LangChain est un framework open-source pour développer des applications basées sur des modèles de langage.
Human: Cela fonctionne-t'il avec AWS Bedrock?
Die DynamoDB-Tabelle für den Nachrichtenverlauf
[HumanMessage(content="C'est quoi LangChain?", ...), AIMessage(content="LangChain est un framework open-source pour développer des applications basées sur des modèles de langage.", ...), HumanMessage(content="Cela fonctionne-t'il avec AWS Bedrock?", ...), AIMessage(content=" LangChain est compatible avec AWS Bedrock, permettant l’intégration et l’utilisation des modèles de langage fournis par AWS.", ...)]
Wichtige Erkenntnisse
LangChain ist ein leistungsstarkes Framework, das zahlreiche Abstraktionen für die schnelle Entwicklung von Anwendungen bietet, die mit LLMs interagieren. Angesichts des rasanten Innovationstempos in diesem Bereich ist es jedoch wichtig, die Entwicklung sorgfältig anzugehen:
- Bevor du dich mit dem Programmieren anhand von Webbeispielen beschäftigst (einschliesslich dieses Artikels), solltest du Zeit investieren, um die Grundlagen von LangChain zu erlernen.
- Vergewissere dich immer, dass du die neueste Version des Frameworks verwendest, um veraltete Funktionen zu vermeiden.
- LangChain ist zwar aufgrund seines modularen Charakters ein flexibles und leistungsstarkes Tool für die Arbeit mit LLMs, aber die effektive Integration dieser Module für deinen spezifischen Anwendungsfall kann komplex sein.
- Sei bereit, dich anzupassen und innovativ zu sein, da Standardlösungen deine individuellen Anforderungen möglicherweise nicht vollständig erfüllen.
- Die Verwendung strukturierter Ausgabe garantiert nicht, dass das Modell deine gewünschte Antwortstruktur einhält. Du benötigst daher einen Fallback-Mechanismus. Beachte ausserdem, dass das Modell möglicherweise falsche Referenzen generiert, die nicht in deiner Wissensdatenbank enthalten sind, wenn du in deiner strukturierten Antwort nach Referenzen fragst.
Wenn du diese Lektionen im Hinterkopf behältst, bist du besser gerüstet, um die Fähigkeiten von LangChain zu nutzen und gleichzeitig die Herausforderungen zu meistern.


