

Cloud Engineer, aus Ostermundigen
Das fehlende Bindeglied: Wie man mit AWS S3 Vectors vollständige Dokumente abruft
Warum sollte man noch einen weiteren Blogartikel darüber schreiben, wie man AWS S3 Vectors nutzt, wenn es bereits viele solcher Blogartikel und Tutorials gibt?
Weil in allen bisherigen Tutorials, die ich gelesen habe, ein entscheidender Aspekt fehlt: Sie erklären nicht, wie man nach dem Finden passender Vektoren tatsächlich die vollständigen Dokumente wieder abruft. Stattdessen speichern sie winzige Beispiel-„Dokumente“ (oft nur einen Satz) direkt in den Vektor-Metadaten. Dieser Ansatz ist zwar für ein Tutorial, das lediglich die Ähnlichkeitssuche mit Vektoren demonstriert, einfach, bricht jedoch völlig zusammen, wenn es um echte Inhalte geht. Hoffentlich kommt niemand auf die Idee, ganze Dokumente in Vektor-Metadaten zu speichern!
Genau diese Lücke füllt dieser Artikel. Ich werde die Grundlagen, die anderswo bereits gut beschrieben sind, nicht wiederholen. Stattdessen konzentriere ich mich ausschliesslich darauf, wie man mit S3 Vectors und einem S3 Bucket eine vollständige Dokumentenwiedergewinnung implementiert, die:
- deine echten Dokumente in einem normalen S3 Bucket speichert
- Embeddings in S3 Vectors erstellt und indexiert
- die Ergebnisse der Vektorsuche wieder mit den ursprünglichen Dokumenten verknüpft
Im Unterschied zu einer Vektordatenbank, die Dokumentenspeicherung und -abruf für dich übernimmt, verwaltet S3 Vectors lediglich den Vektorindex. Zu verstehen, wie man diese Lücke schliesst, ist entscheidend, um produktionsreife Anwendungen mit AWS S3 Vectors aufzubauen.
Auf hoher Ebene lässt sich die Nutzung von S3 Vectors in drei Schritte für Speicherung und Abfrage zusammenfassen, wie in diesem Diagramm dargestellt.
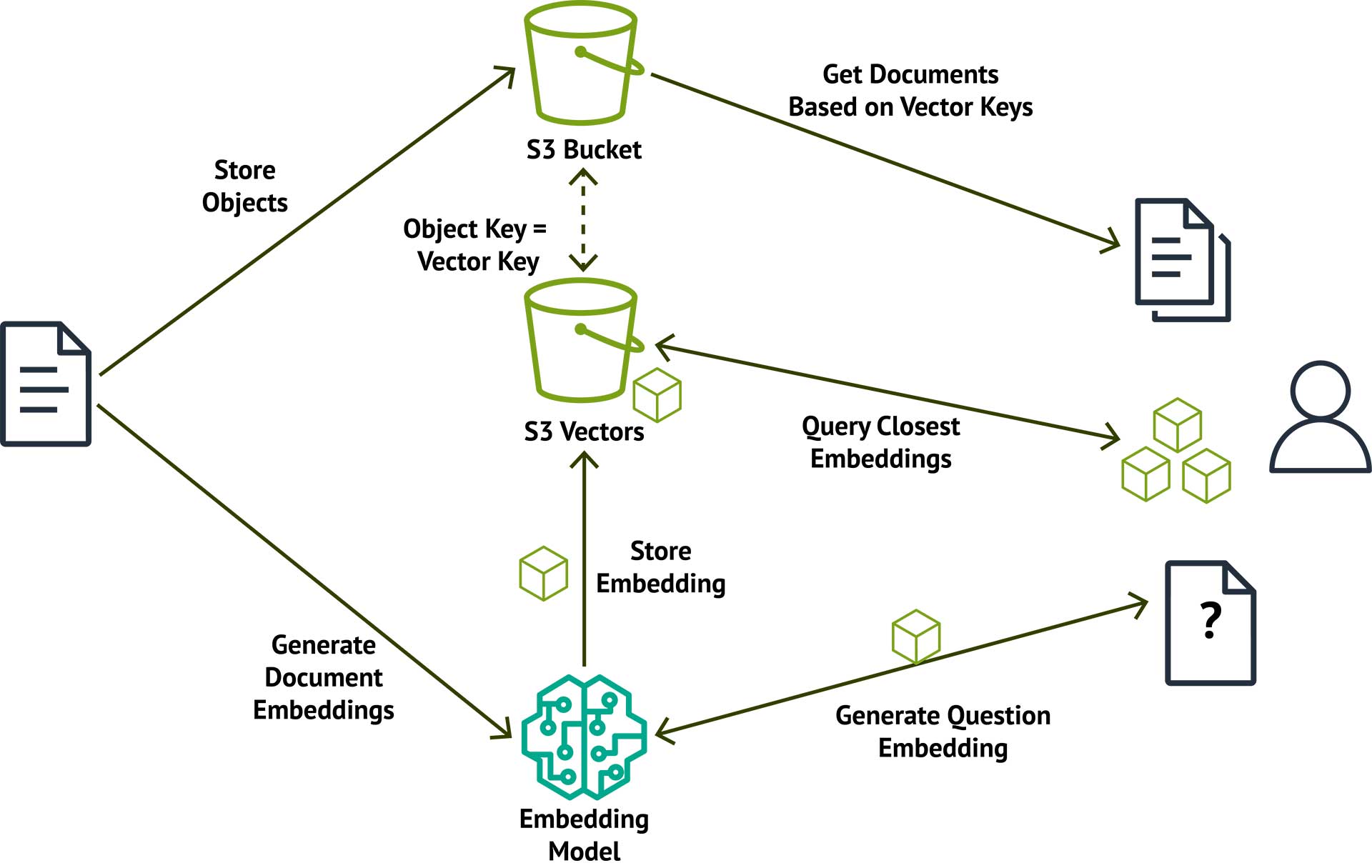
Speichern von Dokumenten und Vektoren
- Die Dokumente in einem normalen S3 Bucket ablegen. In diesem Zusammenhang hashe ich den Dateinamen oder Bezeichner, um den S3 Object Key zu erzeugen,
- Ein Embedding-Modell verwenden, um ein Embedding basierend auf dem Inhalt des Dokuments zu generieren,
- Speichere das Embedding im Vektorindex.
Im Beispiel dieses Artikels handelt es sich bei den Dokumenten um gecrawlte Webseiten, und der S3 Object Key wird durch Hashen der Seiten-URL erzeugt. Die gecrawlten Seiten haben folgendes Format:
{
"content": string,
"metadata": {
"url": string,
"title": string
}
}
Auf hoher Ebene sieht der Code für die 3 Schritte dann so aus:
s3_vectors = boto3.client("s3vectors")
s3 = boto3.resource("s3")
MODEL_ID = "amazon.titan-embed-text-v2:0"
vectors_data_bucket = s3.Bucket(S3_DOCUMENTS_BUCKET_NAME)
vectors = []
for page in pages:
key = hashlib.md5(page["metadata"]["url"].encode()).hexdigest()
# store the actual document in the S3 bucket as a text content
vectors_data_bucket.put_object(
Key=key,
Body=page["content"].encode("utf-8"),
Metadata={
"title": re.sub(r"[^a-zA-Z0-9\s]", "", page["metadata"]["title"]),
"url": page["metadata"]["url"]
}
)
# Generate embedding for the page text
model_response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
body=json.dumps({
"inputText": page["content"],
"dimensions": 1024
}).encode("utf-8"),
)
response_body = json.loads(model_response["body"].read().decode("utf-8"))
embedding = response_body["embedding"]
# Set the vector with the same key as the S3 Object
vector = {
"key": key,
"data": {
"float32": embedding
},
"metadata": page["metadata"]
}
vectors.append(vector)
# Store the vectors in the S3 Vectors index
s3_vectors.put_vectors(
vectorBucketName=S3_VECTORS_BUCKET_NAME,
indexName=S3_VECTORS_BUCKET_INDEX_NAME,
vectors=vectors
)
Abfragen von S3 Vectors und Abrufen von Dokumenten
Wenn du S3 Vectors abfragst, um die benötigten Dokumente zu erhalten, musst du:
- Das Embedding-Modell verwenden, um das Embedding für die Suchanfrage zu erzeugen,
- S3 Vectors abfragen, um die Embeddings zu erhalten, die dem Such-Embedding am nächsten sind,
- Für alle Embeddings in den Ergebnissen den Schlüssel nutzen, um die Objekte aus dem S3 Bucket abzurufen.
question = "What is AWS S3 Vectors?"
documents = []
# Invoke the same model to generate the embedding for the question
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
body=json.dumps({
"inputText": question,
"dimensions": 1024
}).encode("utf-8"),
)
model_response = json.loads(response["body"].read())
question_embedding = model_response["embedding"]
# Use the query embedding to search for similar embeddings in the S3 Vectors index
query_results = s3_vectors.query_vectors(
vectorBucketName=S3_VECTORS_BUCKET_NAME,
indexName=S3_VECTORS_BUCKET_INDEX_NAME,
queryVector={"float32":question_embedding},
topK=3,
returnDistance=True,
returnMetadata=True
)
vectors = query_results.get("vectors", [])
# Retrieve the actual documents from S3 using the keys from the query results
for vector in vectors:
obj = s3.Bucket(S3_DOCUMENTS_BUCKET_NAME).Object(vector["key"]).get()
content = obj["body"].read().decode("utf-8")
documents.append({
"title": vector["metadata"]["title"],
"url": vector["metadata"]["url"],
"content": content
})
Wichtige Erkenntnisse
Im Gegensatz zu einer Vektordatenbank, die die Dokumente für dich speichert und abruft, speichert S3 Vectors lediglich den Vektorindex. Es liegt an dir, die Beziehung zwischen dem Vektorschlüssel und dem tatsächlichen Dokument herzustellen. S3 macht dies einfach, wenn du denselben Schlüssel sowohl für den Dokumentenvektor in S3 Vectors als auch für das Dokumentenobjekt im S3 Bucket verwendest. Auch wenn Speichern und Abrufen dadurch zu einem mehrstufigen Prozess werden, den du orchestrieren musst und der unvermeidlich die Antwortlatenz erhöht, bietet dieser Ansatz erhebliche Kostenvorteile gegenüber dedizierten Vektordatenbanken.
Beachte, dass die Dokumente nicht zwingend in einem S3 Bucket gespeichert werden müssen. Im obigen Beispiel könnte man sich vorstellen, den Seiteninhalt nicht als Objekte in einem S3 Bucket abzulegen, sondern lediglich die Seiten-URLs aus den Vektor-Metadaten zurückzugeben, die downstream gecrawlt würden.


