
Cloud Engineer, aus Ostermundigen
#knowledgesharing #level 100
RDBMS Data Ingestion into an AWS Data Lake with AWS Glue and Apache Iceberg
Reference: This article and demo is an extension of the AWS Big Data Blog article “Implement a CDC-based UPSERT in a data lake using Apache Iceberg and AWS Glue” by Sakti Mishra.
What is the problem?
As mentioned by others before, as the adoption of data lakes grows together with their analytic tools, companies often face a challenge that a lot of the business data still reside on relational databases (RDBMS). But how can you transfer constantly changing data from a database into a data lake based on immutable storage like Amazon S3?
If you synchronize your database with your Amazon S3 data lake with a tool like AWS DMS (Database Migration Service), what you get in your data lake is a pile of transactional data.
|
operation |
id |
Serial_number |
product:_name |
price |
transaction_time |
|
INSERT |
1 |
2564879 |
Gizmo1 |
100 |
1.11.2022 |
|
INSERT |
2 |
6557914 |
Toy1 |
55 |
1.11.2022 |
|
UPDATE |
1 |
2564879 |
Gizmo1 |
120 |
3.11.2022 |
|
INSERT |
3 |
5896147 |
Toy2 |
78 |
4.11.2022 |
|
DELETE |
2 |
6557914 |
Toy1 |
55 |
5.11.2022 |
Table1: Example of transactional data stored on Amazon S3 as a result of the synchronization of a fictional product table using AWS DMS
But this is not what you need to perform any data analytics.
On November 1st what you want to see is the following
|
id |
Serial_number |
product:_name |
price |
|
1 |
2564879 |
Gizmo1 |
100 |
|
2 |
6557914 |
Toy1 |
55 |
On November 3rd
|
id |
Serial_number |
product:_name |
price |
|
1 |
2564879 |
Gizmo1 |
120 |
|
2 |
6557914 |
Toy1 |
55 |
And on November 5th
|
id |
Serial_number |
product:_name |
price |
|
1 |
2564879 |
Gizmo1 |
120 |
|
3 |
5896147 |
Toy2 |
78 |
But how do you go from that pile of transaction data into having in your data lake:
- A view of the current state of the database
- The ability to travel back in time in order to reproduce the results of past analysis or data science experiments?
A demo of a solution
This is where the integration of Apache Iceberg into AWS Glue and Amazon Athena (announced GA in April 2022) can help. Apache Iceberg is an open table format created at Netflix and donated to the Apache foundation in 2018. As per the documentation, Apache Iceberg offers amongst other things:
- Schema evolution : supports add, drop, update, or rename
- Partition layout evolution
- Time travel which enables reproducible queries
In his blog article (referred above), M. Mishra is walking us through a demo of the AWS Glue and Amazon Athena Apache Iceberg integration, assuming the database migration with AWS DMS. In the demo published in this GitHub repository, I propose a full end-to-end demo including:
- an Amazon Aurora PostgreSQL database as a data source
- an AWS DMS instance to ingest the RDBMS transaction data into Amazon S3
- an automatic trigger (as files are written into the RAW Amazon S3 bucket), of the AWS Glue Job to convert the RDBMS transactions data into Apache Iceberg data files
- the deployment of the entire demo using Terraform
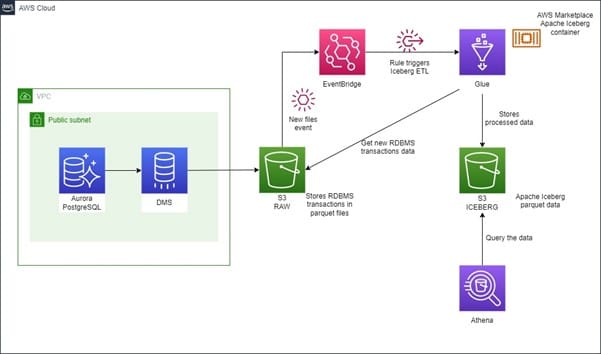
By running this demo you will perform the following steps:
1. Create a table in the Aurora PostgreSQL database and generate fake data. As a result, you will see
a. AWS DMS ingesting the data into Amazon S3, where you will be able to see the database INSERT transaction data.
b. AWS Glue being automatically triggered and converting the database transaction data into Apache Iceberg data files.
2. In Amazon Athena you will be able to see the tables just like you would see them in the PostgreSQL database.
3. You will then update and insert rows in the Amazon Aurora PostgreSQL database ,see AWS DMS ingesting the transactional data into Amazon S3, and AWS Glue automatically converting the new data into Apache Iceberg data files.
4. You will then be able to use Amazon Athena to look at the latest data but also travel back in time to look at the data after the initial ingestion.
We can clearly see two patterns for the CPU intensive operations performed by this benchmark:
1. For memory level <= 512, AWS Lambda on x86 architecture is between 36% and 99% faster than on ARM architecture.
2. If the performance gap between AWS Lambda functions running on ARM vs x86 closes as memory increases, the function running on x86 architecture remains about 16% faster.
Conclusion and lessons learned
The integration of Apache Iceberg with AWS Glue and Amazon Athena is a very good addition to the AWS data analytics service portfolio to easily transform piles of transaction data into database-like table views, which can be queried using the Athena DDL.
There are a few things to consider regarding this integration.
Apache Iceberg needs a timestamp, that will be used to travel in time and allow you to have a table view of the data at a certain point in time. I see two main strategies with this:
- You add in the source database tables a field to record the time any transaction was performed and you set Apache Iceberg to use that timestamp
- If you do not already have such a field in your table schema and you cannot update it, you can use the AWS DMS ingestion time.
The drawback of the second approach is that you will lose precision in your ability to travel back in time to the frequency of your data ingestion. If you synchronize once a day, you will not be able to query the data at a specific time of day (this is the approach implemented in the demo).
There are also two limitations that I found about automating the deployment through infrastructure as code. :
- You cannot deploy the Apache Iceberg connector for AWS Glue from the AWS Marketplace connector through code.
- You cannot create the Apache Iceberg compatible Glue tables through code. As of now it has to be created through an Amazon Athena query. This is why this demo creates an Amazon Athena saved query that is run manually. This can be automated further using an AWS Lambda function.