Cloud Engineer, aus Ostermundigen
#knowledgesharing #level 100
Comparing AWS Lambda on ARM vs x86 architectures
In September 2021, AWS announced AWS Lambda Functions powered by AWS Gravition2 ARM processor and stated that:
“Lambda functions powered by Graviton2 are designed to deliver up to 19 percent better performance at 20 percent lower cost”
In this article we investigate the gotchas of this claim.
The benchmarking
In order to test this claim, we used some Python code with the Numpy library to perform some complex matrix calculations to simulate CPU intensive operations for benchmarking.
Using 300x300 float matrices the benchmarking code performs multiple:
1. Matrix multiplications
2. Vector multiplications
3. Matrix Singular Value Decomposition
4. Matrix Cholesky Decomposition
5. And Matrix Eigenvector Decomposition
The AWS Lambda Function was packaged and deployed on both ARM and x86 architectures. We used the AWS Lambda Power Tuning tool to execute both functions with different memory amounts between 128MB and 5120MB.
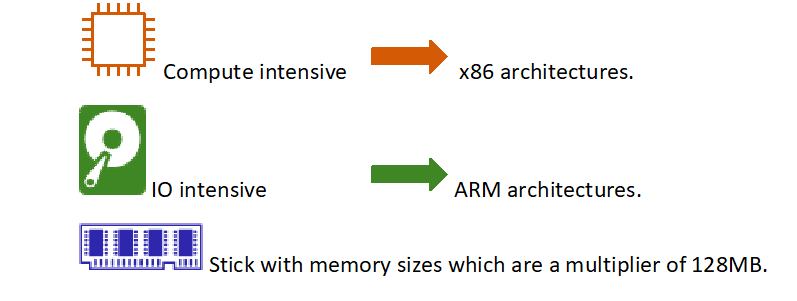
It should be noted that, when configuring your AWS Lambda Functions, you should stick with memory sizes which are multipliers of 128 (e.g., 128, 256, 384, 512, 1024…). Doing otherwise generates memory management overhead reducing the function performances.
The results
The results at all memory levels are as follows:
If we zoom-in at memory level above 512MB for clarity we get the following results:
We can clearly see two patterns for the CPU intensive operations performed by this benchmark:
1. For memory level <= 512, AWS Lambda on x86 architecture is between 36% and 99% faster than on ARM architecture.
2. If the performance gap between AWS Lambda functions running on ARM vs x86 closes as memory increases, the function running on x86 architecture remains about 16% faster.
ARM vs x86 in the real world
Working on some customer project where we were trying to minimize the response time of an AWS StepFunction orchestrating multiple AWS Lambda functions, we performed some side-by-side comparison. To do so, we deployed the entire process in parallel, one with all AWS Lambda Functions configured with an x86 architecture, one with all the functions configured with an ARM architecture. We observe that in general
• Compute intensive functions were faster on x86 architectures.
• Other functions were faster on ARM architectures.
Migration effort - is it that simple?
In that same blog announcement, AWS states
“The change in architecture doesn’t change the way the function is invoked or communicates its response back.”
This suggests that the migration is as simple as changing the AWS Lambda function architecture parameter from ARM to x86.
Although that might be true in some cases, this is unfortunately not the full picture. If your function uses non default AWS Lambda compiled libraries (e.g., the benchmarking function imports the Python Numpy library which uses compiled C libraries), switching the architecture from x86 to ARM will break the function as the library has to be recompiled for the architecture it is running on.
In such cases, just changing the AWS Lambda function architecture parameter is not enough. You need to repackage your libraries, which, depending on the language and how you package and deploy these libraries can be more or less complicated.
Conclusion
The answer to whether AWS Lambda function executes faster on ARM vs x86 architecture, is as often: “it depends”.
From the benchmark we performed at Axians Amanox, the rule of thumb seems to be that – for now:
The bottom line is that you need to test for your particular applications and test all functions individually depending on the operation they perform. The results will probably show that you will need to run a mix of both.