 Group
Group
Case Study:
SBB Cargo
The Challenge
The Problem: Digital Twin
Our customer needed to extract the most recent data points from a wide range of live data provider. Those data are continuously acquired through a set of data pipelines (as described in this blog article). Also the customer wanted that the most recent data points were made available through a HTTP REST API. The resulting service has been called «Digital Twin», because it collects and exposes the most recent data for a wide array of data sets coming from physical objects, making them a «digital representation» of objects› states.
Technical challenges
The data has various structure and formats, according to which service they come from. Many of these services provide near real time data which are acquired with a rate that vary from 15 minutes to 1 second. Those data need to be filtered in real time, normalized, and persisted in a database that can be subsequently queried from the API users.
The Solution
A serverless solution based on AWS
We wanted the solution to be consistent with data pipelines architecture and with the «serverless design philosophy» which we’ve successfully embraced together with the customer.
We also wanted to keep using tools and managed services provided by AWS. During architectural design, we kept an eye to allow easy maintenance and incremental extensions. The resulting architecture is depicted in the following picture and has been described using Terraform as IaC tool.
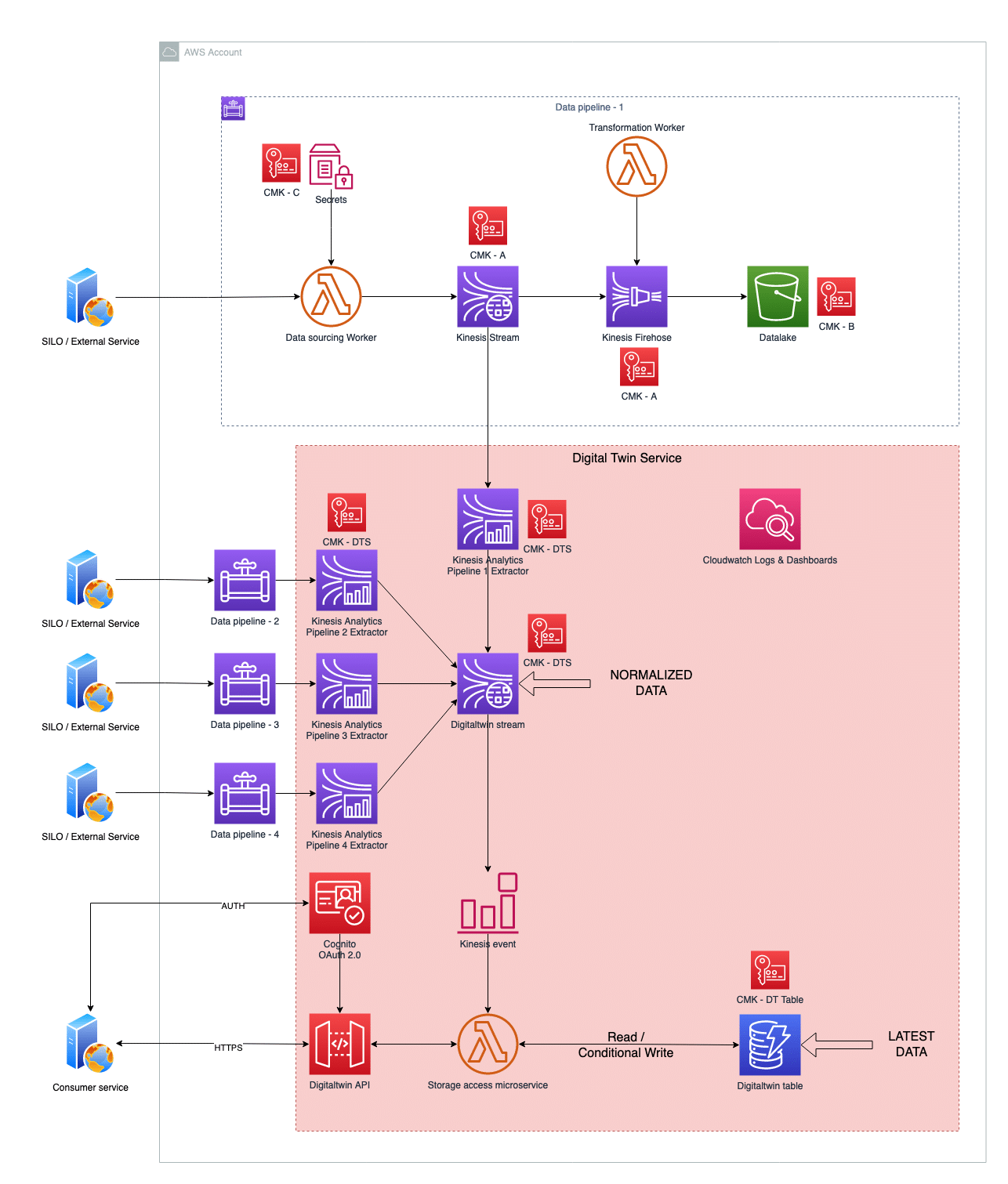
Tools & Technologies
Digital Twin service takes fully advantage of the pluggability of data streaming architecture: it collects data by hooking to the Kinesis Streams/Firehose buffers which are deployed in every data pipelines.
The services used in this implementation are:
- AWS Kinesis Analytics as data extraction service
- AWS Kinesis Stream as data stream service provider
- AWS Lambda as computing infrastructure to run storage access microservice
- Amazon DynamoDB as persistence layer
- AWS API Gateway to provide HTTPs REST interfaces
- Amazon Cognito to provide OAuth2 infrastructure
- AWS KMS as encryption service
- AWS IAM for policy / roles definition
- AWS CloudWatch to provide logging infrastructure and observability.
What follows is the description of each component.
Data Extractor => AWS Kinesis Analytics:
Once data are retrieved by pipeline’s sourcing workers, they are buffered for a configurable amount of time in Kinesis Stream, being available for near real-time analysis, ETL transformations or continuous monitoring. By creating a Data Extractor as Kinesis consumer, we were able to leverage the almost instant data availability in Kinesis and modular architecture of data streaming services. Instead of implementing a Kinesis consumer from scratch, we’ve opted for using Kinesis Analytics and its SQL capabilities. Hence, data extractor became a simple Kinesis Analytics jobs which does 3 things: mapping data properties («data templating»), continuously extracting a subset of them («data pumping») and providing a normalized output which is sent to Digitaltwin Kinesis Stream («data delivery»). By hooking a different data extractor for every data pipeline with consistent output, we’ve achieved data normalization across all data pipelines. All this has been done by just defining a Kinesis Analytics Terraform resource and a set of SQL statements saved in a single file for every Extractor.
Digitaltwin stream => AWS Kinesis Stream:
A data stream with short data expiration is a good choice to buffer extracted data as they wait to be persisted (or further analyzed in future improvements of this architecture). A good choice on AWS is to use Kinesis Stream.
Storage Access microservice => AWS Lambda:
We’ve used AWS Lambda as the computing infrastructure to build a serverless microservice that writes and reads data to/from the persistence layer. Lambda has been chosen because of its flexible invocation model: the code to access the persistence layer is the same regardless which service needs it and it can be triggered by a Kinesis Event (data coming from Extractors) or by an API Gateway one (REST API request by an external consumer service).
Persistance layer => Amazon DynamoDB:
We needed to store the most recent value for a given component metric. This access pattern can be efficiently served by a K-V store, where the Key is Component.MetricName and the value is the actual metric (plus some metadata to identify its lineage). DynamoDB is a serverless NoSQL store which fits perfectly in this scenario. Thanks to conditional writing capability it’s simple to enforce that a write attempt is successful only with the most recent data. Through autoscaling capabilities DynamoDB is also capable of absorbing any amount of access load.
HTTPs REST interfaces => AWS API Gateway:
To provide external access to Digital Twin data we’ve deployed an API Gateway which has been integrated with Storage Access microservice (that retrieves and serves data). It’s a serverless solution, fully integrated with AWS Lambda for computing needs and Amazon Cognito for user/service-based access control.
OAuth 2.0 infrastructure => Amazon Cognito:
Implementing OAuth 2.0 server side is not trivial. Cognito offers a set of tools and resources that makes a lot easier to implement OAuth 2.0 flows, providing AUTH endpoints and signed JWT tokens to authorized users/service clients. It’s also fully integrated with API Gateway for simple JWT auth checks, while more complex authorization logics can be implemented by using a Lambda Authorizer in API Gateway.
Security/1 => KMS:
Data in transit and at rest are encrypted using KMS with scope limited CMKs (Customer Master Keys)
Security/2 => Lambda specific role & policies:
Lambda functions run using scoped-down permissions, expressed through IAM policy documents attached to a specific role which is assigned to the lambda.
Security/3 => Kinesis Analytics specific role & policies:
Kinesis Analytics execution is linked to scoped-down permissions, expressed through IAM policy documents attached to a specific role which is assigned to the Kinesis Analytics.
Logging and observability => CloudWatch:
All logs (execution, access, errors) are collected by CloudWatch. Operational metrics are plotted in a specific CloudWatch Dashboard, providing an easy way to set custom alarms for any kind of DevOps activities.
Everything in this implementation is described using IaC and under version control in a git repository. A CICD pipeline is attached to the repository, providing automatic infrastructure build and deployment at every new commit.
Conclusion
Building this Digital Twin service was not trivial given the many moving parts and heterogeneous data sources, with different acquisition rates and structure. By adopting the data pipeline paradigm and by integrating the service in that paradigm, leveraging the data stream architecture, the problem can be divided in smaller and simpler parts, making it easier to solve from the methodological point of view.
By using the tools and services provided by AWS, all the infrastructure and application server provisioning is offloaded completely to the cloud provider, letting us developers and our customer to focus only on business logic and making the implementation achievable in few days by a single developer with greatly reduced operational costs.
Maintenance is provided through IaC and git commits. DevOps new services can be easily introduced by leveraging operational metrics, most of them collected in the CloudWatch dashboard for live surveillance. Also expanding the service to future datasets will be as simple as adding a new Kinesis Analytics job and a new SQL set of statements, making this implementation fully modular.
written by

Cloud Engineer, aus Derendingen

Kunde
SBB Cargo
SBB Cargo is a subsidiary of Swiss Federal Railways (SBB) specialising in railfreight and is operated as the Freight division. The headquarters of Swiss Federal Railways SBB Cargo AG, the Freight division’s official designation, are in Olten. In 2013, SBB Cargo had 3,061 employees and achieved consolidated sales of CHF 953 million.[1] In Switzerland, SBB Cargo is the market leader in rail freight, transporting over 175,000 tons of goods every day. This corresponds to the weight of 425 fully loaded jumbo jets.
Partner
AWS
As AWS Advanced Consulting and training partner, we support Swiss customers on their way to the cloud. Cloud-native technologies are part of our DNA. Since the company’s foundation (2011), we have been accompanying cloud projects, implementing and developing cloud-based solutions.








